
Project Members: Ian Dollinger, Tristan Koster
Project Sponsor: Dr. David B. Lowe
We have been approached by the Texas A&M University Libraries’ Professor David Lowe with a machine learning project that will classify research documents. As it is right now, organization of research documents has proven to be very time consuming due to the sheer quantity of research papers that the libraries are responsible for. To help the libraries with classifying documents, Professor Lowe has tasked us with creating a machine learning algorithm that can classify research articles based off of their abstracts into either basic or applied research, with the intention of expanding the project into further classification of research by department or subject matter and beyond. To address this problem, the project team has decided to use a supervised learning approach to train a sentiment analysis algorithm to determine how to classify each document.
Current Progress
At the beginning of the project to get some sense of direction on what kind of words to look for between the two types of articles, basic or applied, word clouds were generated using the wordcloud python library. This produced images that visualized the frequency of the words by making more common words larger than the words that were more uncommon. These images were used to give the project team some sense of what kind of words to look for within the data, but ultimately were not used to train the algorithm for classification.

Two different methods of preprocessing were used on the data. The first method was done using the gensim library to create two different dictionaries one that included only the words from our prelabeled abstracts and another containing all the words from every abstract. This was useful in producing a list of words that we could use to train our model, but ultimately the results produced by this method of aggregation were insufficient. To improve the results the gensim library was used which is found as part of the sklearn library. This was used to take all the words from the prelabeled research abstracts and produce a list of unigram and bigrams. This list was then filtered to only include the n-grams that appeared at a set frequency. This frequency was then tweaked to attempt to achieve better results. The list of unigrams and bigrams was then run through a word vectorizer, with the produced word vectors used to train the model.
In addition to dividing the words from the abstracts into lists of unigrams and bigrams, those words were also vectorized using word embedding techniques to allow numerical comparisons of the words to take place. An example of word vectorization being used to find similarities between words is show below:

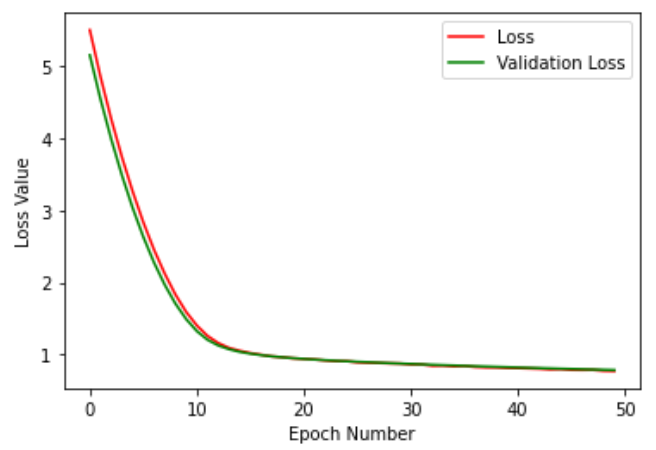
Two models have also been used for training the program. These models were logistic regression and feed forward neural networks. Both of these models produced a validation accuracy of around 62%-71%. These results are from both methods of preprocessing.
Challenges
Currently there is an issue regarding the accuracy of the results that have been produced as they are not as accurate as desired. The current plan to alleviate this issue to work on implementing the BERT model by recommendation from the Tidal TAMU advisors.
Future Plans
If it turns out that the BERT model is not producing sufficient results, further research will need to be done to either find a better method of preprocessing or a model to use to train and analyze the data. If BERT ends up producing results that meet the requirements of the project, then the next steps are to meet with Professor Lowe and see if the trained model works on the rest of the libraries unlabeled data.
Recent Comments