
Project Members: Adityasing Jamadar, Rakshit Soni, Thuc Tran, Olumayowa Olowomeye
Project Sponsor: Dr. Daniel McAdams
Science-fiction books often contain mentions and elaborations of speculative technologies years before their realization. Due to the copious amounts of literature that would be needed to be cycled through for information regarding speculative technology, it would be difficult to go through all that information without the help of machine learning. Using ML, specifically natural language processing, we want to identify when a fiction writer has speculated a technology in a given text. Specifically, the AI should be able to categorize the speculated technology into different areas ranging from clothing, communication, weapon, space technology, among others.
Progress – Summer 2020
Our project began in the summer of 2020 with the team of six divided into two groups of three members- data mining and classification. The data mining group dealt with identifying websites with free books to download the science fiction books. The Data Mining team used Beautiful soup for scraping the data and extracting the excerpts with word indicating technologies. The Data Mining team hit a roadblock when one of the key members left the team to pursue different opportunities and ultimately left with just a member who had limited experience in Python. Since then there was no progress in data collection and the classification team worked with limited available data.
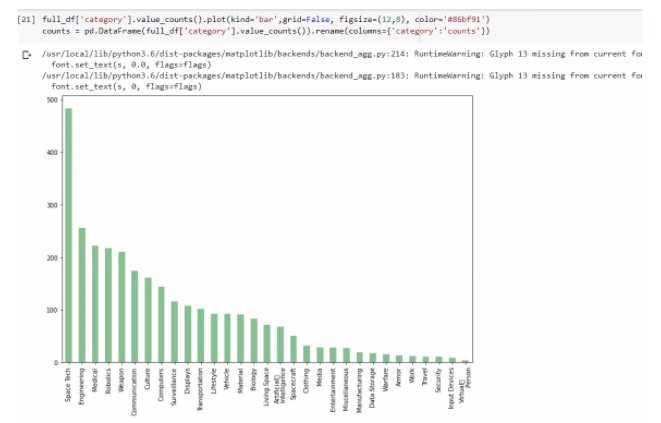
The classification team dealt with cleaning the unnecessary parts of the texts like punctuation to make the data more readable. They also helped in fast processing of the data based on keywords mentioned in the excerpts and further categorized into speculative technologies like space technology, weapon, communication, etc.
Progress – Fall 2020
Due to most of our members being new or having little understanding regarding machine learning let alone NLP, our efforts have been focused on researching and understanding NLP, AI, as well what was done before us and how we can improve on it. Our research has been focused on learning more about machine learning as a whole and learning about NLP and the BERT technique that we will be using.
The project is currently split into 2 parts: a classification part and a data mining part. Within the data mining task, we are collecting the books and manually identifying new technologies. We ran into some problems as we are only able to download about 200 books before the website (gutenberg) we are getting the books from seems to stop us. Within Classification,we are categorizing the new technologies. We have some data that we are using that contains technologies and the excerpts they are described in from different books as well as a category for the technology. This is being used to train the AI. The problem here is a low accuracy, so we will have to do some more fine tuning with the BERT technique and probably clean our data a bit more.
Some of the problems we are focusing on are the same as mentioned in the previous report. We have enclosed the problem information and images below:
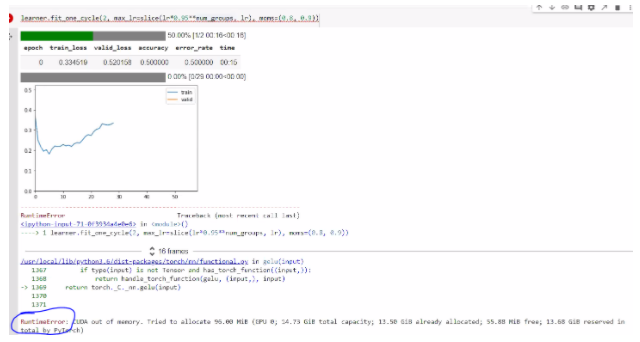
We have used BERT and we are stuck on the “CUDA out of memory error” detailed below.
Challenges
We are trying to reduce the batch size since we are getting an error of running out of memory after resampling. This happens when ever we are training the model.
Future Goals
While we are still learning about machine learning and BERT, we want to focus our efforts on the datamining side and see if we can fix the errors and problems there. The website we are downloading the books from seems to have updated its format and many of the links we were using are now invalid so we will have to work around that. Once we feel more confident in our knowledge of NLP we will then focus our attention on the Classification side and try to figure out ways to improve our methods there. We also want to improve our current communication with our sponsor.
Responsibilities
Adityasing: Improve knowledge of python and NLP
Rakshit: Research more into NLP and BERT
Thuc: Improve knowledge of python and NLP
Olumayowa: Research more into NLP and BERT algorithm
Recent Comments