
Project Members: Robert Blum, Osman Hernandez, Xiarou Hu, Rohit Jadhav, Sindhu Kamineni, Mannan
Mendiratta
Project Sponsor: Dr. Surya Sarat Chandra Congress
We are creating a model, with the use of machine learning, that is capable of identifying and highlighting road cracks. It takes as input aerial images of roads, such as highways, and outputs a segmentation mask/map, or highlighting, of all detected cracks in the road. This is for the purpose of aiding infrastructural repair and monitoring. We are developing an image classification model, and an image segmentation model for the purpose of completing this task. In the future, we plan on incorporating 3D point clouds into our data sets. Additionally, we will continue this kind of application with other infrastructure data sets, such as buildings, columns, and walls.
Current Progress
We are currently developing an image classification model, and an image segmentation model. We plan on passing the classification model over small regions of the original images, to detect whether there exists a crack in each given region. If there is a crack, we will pass the image into the image segmentation model, to obtain the highlighted versions of the cracks.
Here is an image of the planned pipeline:
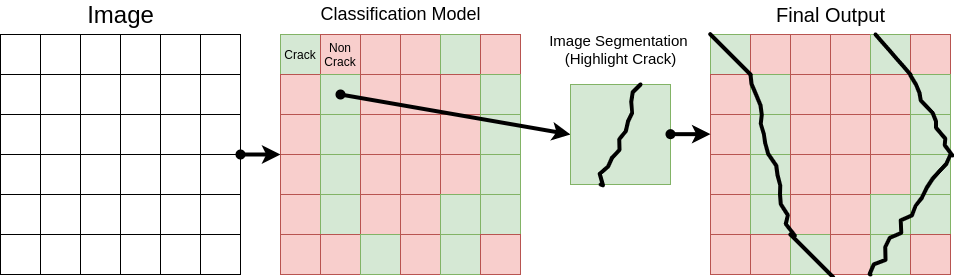
We may be able to use publicly available datasets with images of cracks for training, for both the classification and segmentation models. Segmented image data sets include CrackTree, CrackForest, EdmCrack600, etc. We will likely also generate our own segmented training data. Using H.O.G. or another edge detection algorithm, we could obtain a draft highlighting of the cracks, which can then be manually “cleaned up” to produce a full segmentation.



We are using PyTorch currently for the image classification model, and will use TensorFlow for the image segmentation model, with a U-Net network architecture.
We are also planning on possibly doing image imputation/inpainting, so that we can use images with occlusions (such as vehicles covering the cracks) for input.
Challenges
We are not particularly stuck on anything, however we would like to know if there are optimal architectures or pre-existent models for performing these tasks, and what the best practices are for obtaining training data, as well as for preprocessing input.
Future Plans
In the future, we plan on using 3D dense point clouds, to further our Infrastructure analysis. We also plan on moving on to data sets besides roads, such as buildings, columns, walls, and so on.
Recent Comments